It finds the problem.
You don't write the rules.
Epok watches your logs, metrics, traces, infrastructure, RUM, and replay and surfaces what broke — automatically, from your first hour. No dashboards, no alert rules, no thresholds to tune.
Every failure that should page you — explained when it fires.
Each one arrives with the example alert you'd actually get, the cause already identified, and every claim linked to the line, span, or metric behind it. Detection runs the same on every tier.
An error you've never seen
A message that never appeared in your recent history, surfaced within minutes — the first sign of a fresh failure, tied to the deploy that introduced it.
A service gone quiet
A service that stops logging when it normally logs steadily. The most dangerous failure: no error, just absence.
Spikes, drops, and drift
Volume and rate that jump, fall, or slowly drift away from each service's learned daily and weekly normal.
Regressions in the golden signals
Latency, error rate, and saturation crossing what's normal for a service — measured against the baseline it learned, not a number you guessed.
Failures that cascade
Upstream failures, retries, and circuit-breaker trips connected into the cascade they cause — and errors that mean the same thing folded into one alert.
Your stack's known failure modes
Crash loops, resource exhaustion, queue saturation, slow queries, auth abuse — the specific ways your platform breaks, caught from the first log line.
A host or node gone dark
A host, node, or agent that stops reporting — no heartbeat, no metrics, no logs. Marked down the moment it goes silent, so you page on the box itself, not just its symptoms downstream.
Capacity, forecast before it fills
A disk, volume, or quota projected to run out from its current trajectory — paged with an ETA while you can still act, not after it breaks.
Error-budget burn
Burn-rate alerts on the SLOs you define, with short- and long-window confirmation — warned before the budget runs out, not after.
See these fire on live data — no signup.
Open the live demo →Need something specific? Write it in search syntax.
For the cases the automatic detection doesn't cover, write a threshold rule ("alert when this search crosses a number") or a composite rule ("alert when two conditions are both true"). Same syntax you search with — no separate language to learn. Rules are plain JSON: version them in the repo next to your service code.
{
"name": "Payment refund burst",
"query": "service:payment AND _msg:refund AND amount > 1000",
"condition_op": "gt",
"condition_value": 5,
"window_seconds": 300,
"severity": "critical",
"for_duration_seconds": 60,
"channel_ids": [12, 8]
}Visual builder or JSON — you pick. Both use the same schema as the API.
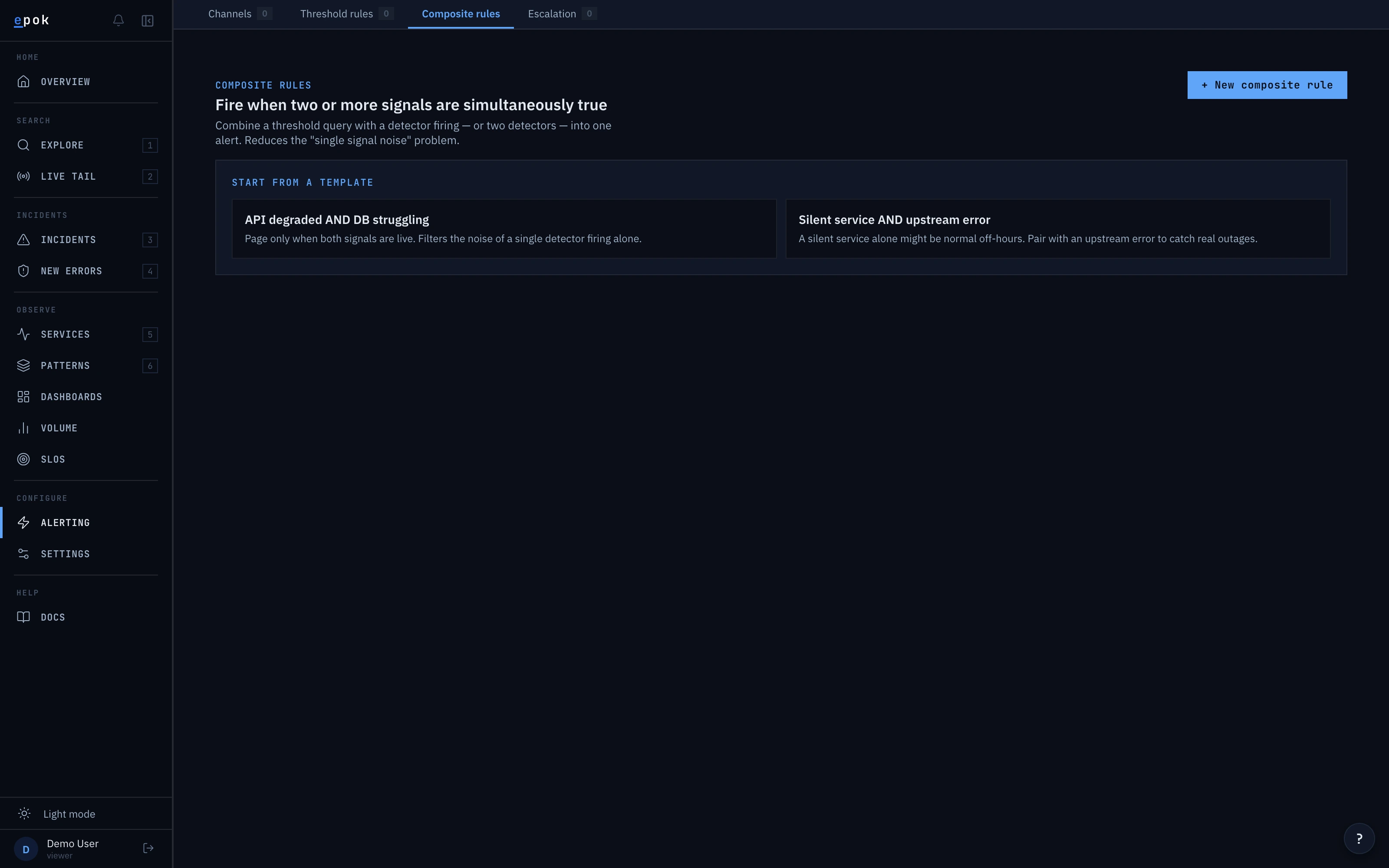
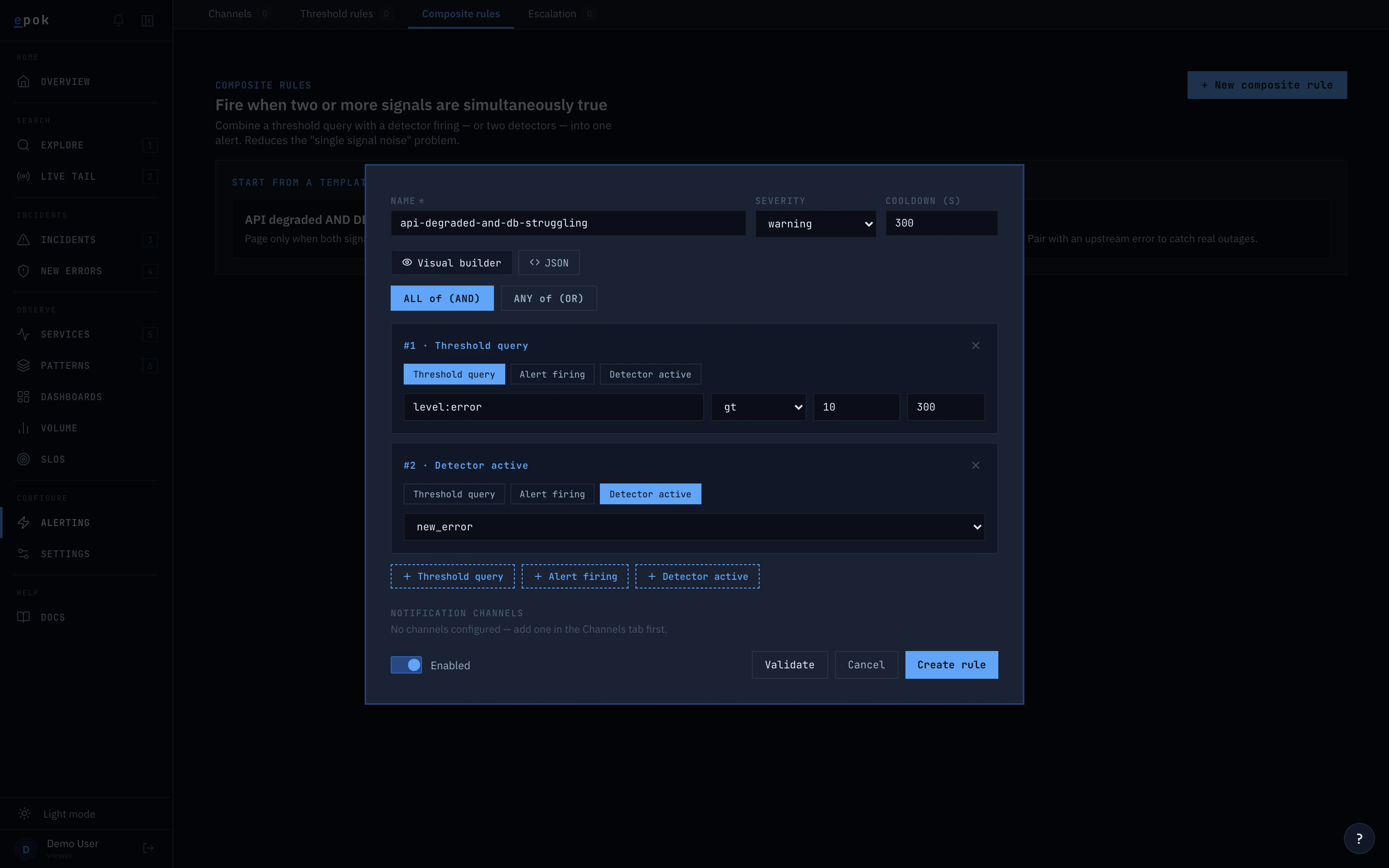
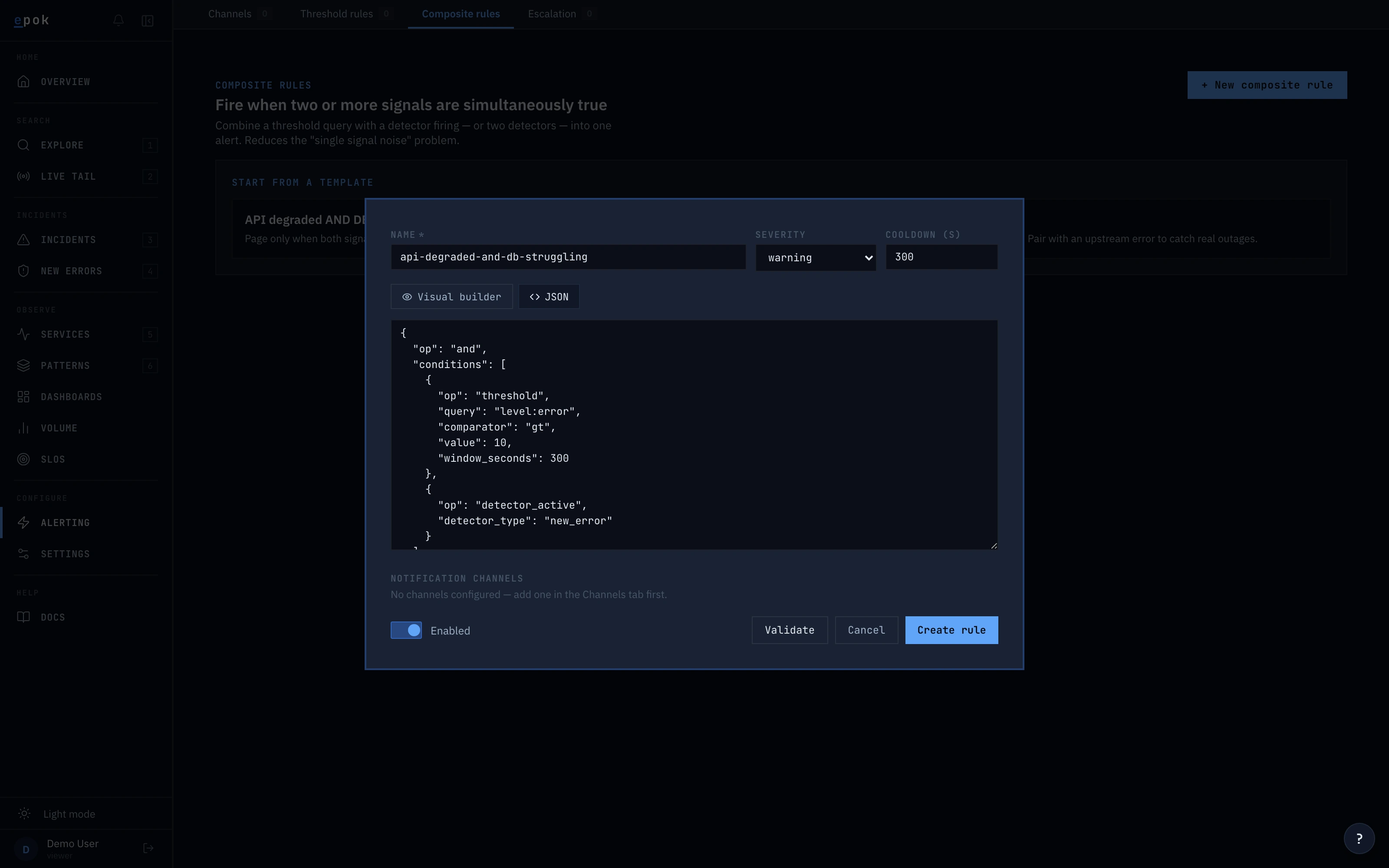
Every detection is auditable.
None of this is a black box. Every alert carries the evidence that triggered it — the log lines, the spans, the baseline it deviated from — and that evidence is checked before the alert renders. When the AI drafts a cause, each sentence links back to the lines behind it. You verify the finding; you don't take it on faith. That's the difference between a detector you can put on the pager and one your team eventually mutes.
See it catch a real failure. No signup.
Open the live demo and watch detection fire on real-shape data — every alert cited back to the line behind it.