Signals in. Answers out.
Every layer is inspectable.
Detection runs across your signals. When something fires, the investigation correlates logs, metrics, traces, infrastructure, RUM, and replay on one canvas by shared trace ID — and every layer is inspectable.
watch the whole mechanism on one incident — detection to cited cause, end to end · 2:54 · narrated
Anything that speaks HTTP.
Logs, metrics, traces, RUM, and session replay — all on one meter. Send logs, metrics and traces via FluentBit, Vector, Promtail, the OpenTelemetry collector, syslog forwarders, CloudWatch subscription filters, or a curl script — no SDK to embed, no proprietary agent required. (RUM and session replay add a lightweight browser snippet.) Typically searchable within seconds of POST. Live tail measured p50 ~14 ms / p95 ~118 ms from arrival to your screen (N=40, our prod) — a measured latency figure, not a competitive benchmark.
Field extraction without a schema.
Severity, service, hostname, and trace IDs are extracted automatically. Custom fields are stored as-is — no schema to declare, no cardinality tax. JSON is parsed; raw text is kept searchable.
Template clustering.
Every line is hashed to a stable template — variable values (UUIDs, IPs, timestamps) are abstracted out, leaving the structural shape. The same error across a thousand unique strings collapses to one pattern fingerprint.
Per-service rolling distributions.
A rolling distribution per service per hour-of-week. Seasonal patterns are learned, so a 3am spike on a quiet weekend service isn't measured against peak-hour production. Detection scores deviations against this baseline.
Detection runs in parallel.
Learned detection consumes the baselines and flags deviations; rule-based detection matches your stack's known failure modes from the first line. Everything runs in parallel, and each candidate carries a confidence score.
Fingerprint dedup + ack-aware quieting.
Candidates that share a fingerprint are folded into a single alert with a fire count. Repeat-fires that don't get acknowledged learn to stay quieter — the pager isn't asked twice for the same thing. Acknowledged-and-not-resolved alerts suppress duplicates until they're closed.
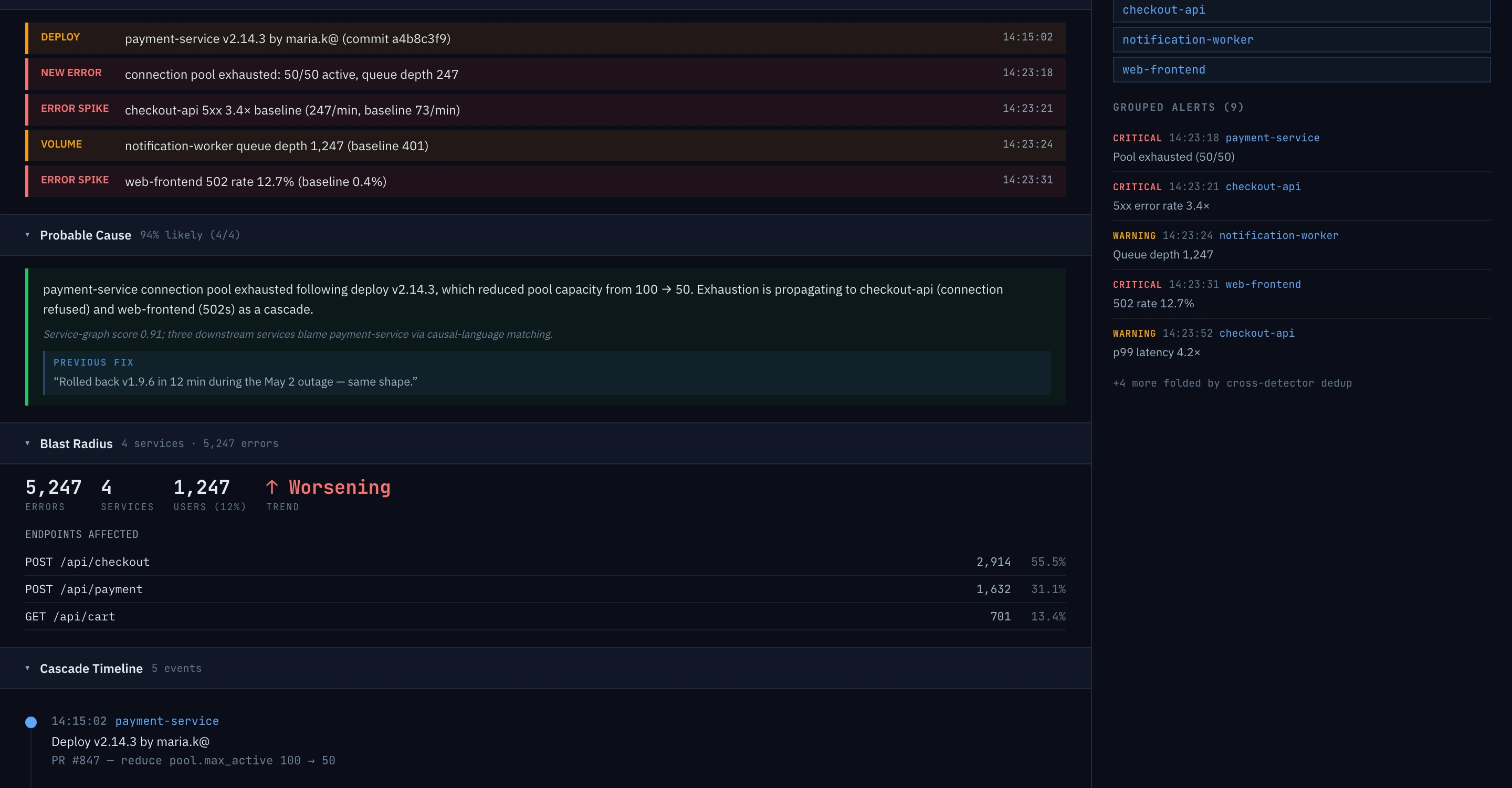
Cascade graph across services.
When two or more detectors fire on related services within a time window, they're folded into one incident. Logs, traces, RUM, and session replay are stitched by shared trace ID; metrics and infrastructure correlate by service and time window — "X called Y and got a timeout" is a directed edge. Cascades present as one page, not five.
Root-cause scoring + blast radius.
Each candidate cause gets a readable score — origin vs. victim classification, failure type (TIMEOUT / OOM / AUTH / CONFIG / CONNECTION / CRASH), and a recency-weighted evidence count. Blast radius (affected services, users, endpoints) and "what changed" (recent deploys, config diffs) are computed in parallel.
LLM writeup, cited evidence.
This layer drafts a 2–3 sentence root-cause hypothesis from the diagnosis. Every claim links to the specific log lines that produced it. The output is what arrives in Slack and PagerDuty — what happened, probable cause, what to check first. AI included on every tier, including the trial.
Grades its own certainty.
Before the page goes out, a calibration gate weighs the evidence against how confident the engine actually is. When the signal is strong, it commits the verdict. When it's thin, it says so — and tells you what to check next instead of guessing confidently. Confidence is measured against real outcomes, not asserted.
Want to see all ten in action?
The live demo runs the full pipeline on a synthetic log stream. Click any alert to see the candidates, the suppressed dupes, the cited evidence — every layer leaves an audit trail.